A inteligência artificial ChatGPT atraiu o interesse em diferentes campos de atuação, pois oferece uma interface de linguagem com impressionante competência conversacional e capacidade de raciocínio em vários domínios. Mas como o ChatGPT é treinado com linguagens, atualmente ele não é capaz de processar ou gerar imagens do mundo visual.
Na contra partida, modelos como Transformers ou Stable Diffusion, apesar de mostrarem grande compreensão e capacidade de geração imagem, eles são especialistas em tarefas específicas com entradas e saídas de uma única vez.
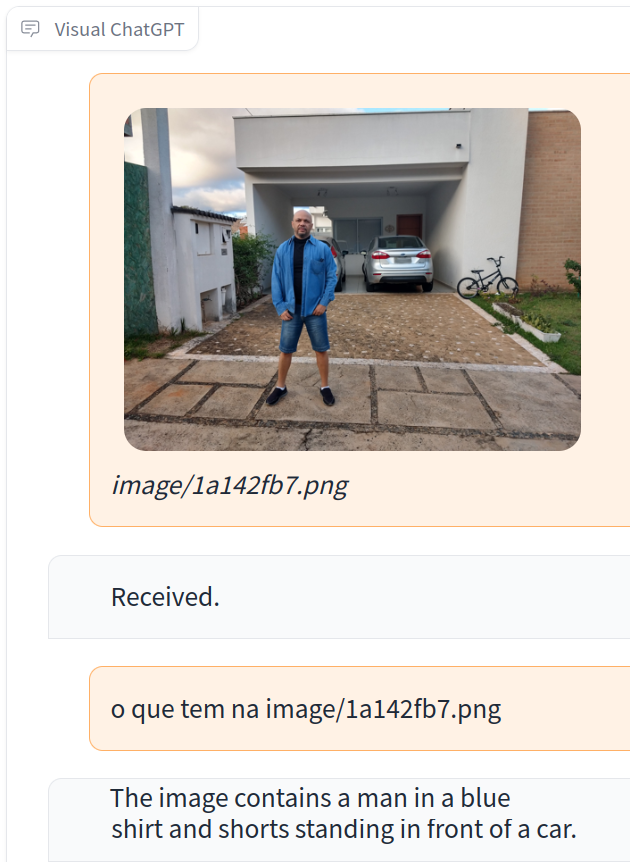
Então para facilitar esta integração entre ambos recursos, foi construído um sistema chamado Visual ChatGPT (ACABEI DE INSTALA NA MINHA MAQUINA!), incorporando diferentes Modelos para processamento de imagem. Assim permitindo que o usuário interaja com o ChatGPT enviando e recebendo não apenas textos, mas também imagens.
É possível também fornecer questões de imagens complexas ou instruções de edição imagens que exigem a colaboração de vários modelos de IA com etapas múltiplas. Podemos contar com o recursos de envio de feedback e solicitar correções do trabalho processado. Foi desenvolvido uma série de prompts para injetar as informações do modelo visual no ChatGPT, considerando modelos de múltiplas entradas/saídas e modelos que trabalham com feedback visual.
Os experimentos que efetuei mostram que o Visual ChatGPT abre a porta para analisar imagens no ChatGPT com a ajuda dos Modelos de Visão Computacional. O sistema está disponível com o código fonte aqui: https://github.com/microsoft/visual-chatgpt
Instruções de Instalação
# Download do repositório
git clone https://github.com/microsoft/visual-chatgpt.git
# Entre na pasta recém criada
cd visual-chatgpt
# Crie um ambiente com python 3.8
conda create -n visgpt python=3.8
# Ative o ambiente recém criado.
conda activate visgpt
# Instale os requisitos básicos
pip install -r requirements.txt
# Insira a sua licença
export OPENAI_API_KEY={Your_Private_Openai_Key}
# comando para 4 GPUs Tesla V100 32GB
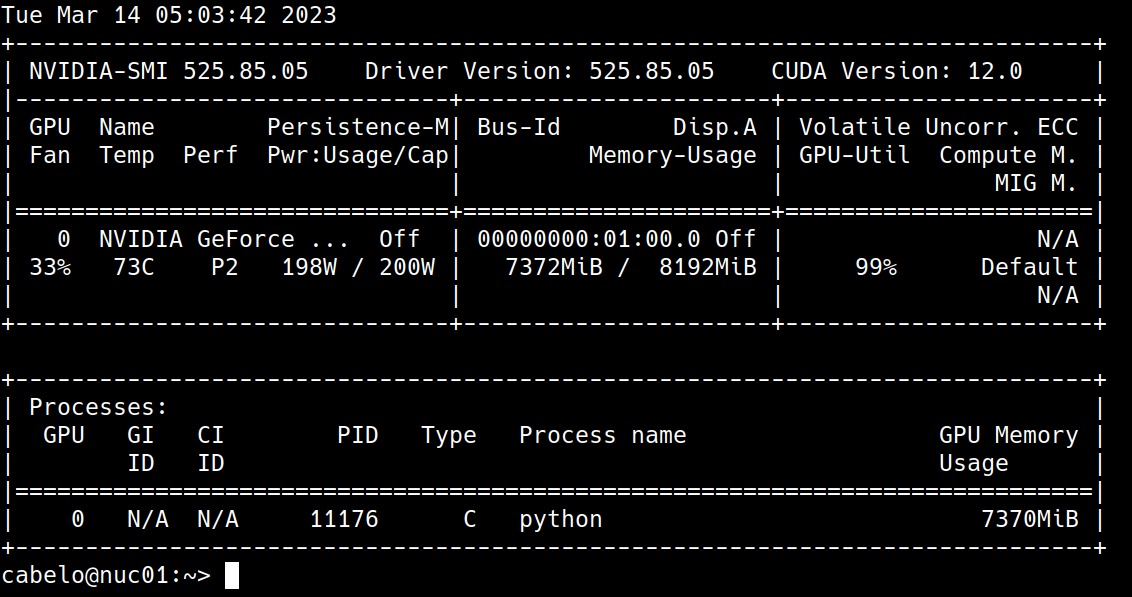
python visual_chatgpt.py --load "ImageCaptioning_cuda:0,ImageEditing_cuda:0,Text2Image_cuda:1,Image2Canny_cpu,CannyText2Image_cuda:1,Image2Depth_cpu,DepthText2Image_cuda:1,VisualQuestionAnswering_cuda:2,InstructPix2Pix_cuda:2,Image2Scribble_cpu,ScribbleText2Image_cuda:2,Image2Seg_cpu,SegText2Image_cuda:2,Image2Pose_cpu,PoseText2Image_cuda:2,Image2Hed_cpu,HedText2Image_cuda:3,Image2Normal_cpu,NormalText2Image_cuda:3,Image2Line_cpu,LineText2Image_cuda:3"Memória utilizada da GPU
Aqui listamos o uso de memória da GPU para cada modelo, você pode especificar qual deles você deseja utilizar:
| Modelo | Memória da GPU (MB) |
|---|---|
| ImageEditing | 3981 |
| InstructPix2Pix | 2827 |
| Text2Image | 3385 |
| ImageCaptioning | 1209 |
| Image2Canny | 0 |
| CannyText2Image | 3531 |
| Image2Line | 0 |
| LineText2Image | 3529 |
| Image2Hed | 0 |
| HedText2Image | 3529 |
| Image2Scribble | 0 |
| ScribbleText2Image | 3531 |
| Image2Pose | 0 |
| PoseText2Image | 3529 |
| Image2Seg | 919 |
| SegText2Image | 3529 |
| Image2Depth | 0 |
| DepthText2Image | 3531 |
| Image2Normal | 0 |
| NormalText2Image | 3529 |
| VisualQuestionAnswering | 1495 |