Imagine entrar em um ambiente virtual que não foi completamente desenhado por uma equipe de artistas, programadores e desenvolvedores. Em vez de carregar um mapa pronto, armazenado previamente no computador, o cenário é criado continuamente por uma inteligência artificial enquanto o usuário caminha, dirige um veículo, movimenta um personagem ou altera a direção da câmera. Essa é a proposta do ABot-World-0, um modelo desenvolvido pelo AMAP CV Lab para gerar vídeos interativos condicionados às ações do usuário.
O paper do projeto, intitulado “ABot-World-0: Infinite Interactive World Rollout on a Single Desktop GPU”, foi publicado no arXiv em julho de 2026. O trabalho representa uma mudança importante na evolução dos sistemas de geração de vídeo, pois não se limita à criação de pequenos clipes previamente determinados. O objetivo é produzir um mundo visual que continue sendo gerado conforme o usuário interage com ele, criando uma experiência que se aproxima de um videogame, mas sem depender exclusivamente de cenários, movimentos e animações programados antecipadamente.
Muito além de um gerador tradicional de vídeos
Nos geradores de vídeo convencionais, o usuário escreve uma descrição e aguarda a inteligência artificial produzir uma sequência com alguns segundos de duração. Depois que o vídeo é concluído, não existe uma maneira real de entrar naquela cena, mudar sua direção ou decidir o que acontecerá em seguida. O ABot-World-0 funciona de forma diferente: o usuário envia comandos pelo teclado e o modelo utiliza essas ações para determinar como os próximos quadros devem ser produzidos.
Ao pressionar uma tecla para avançar, virar, recuar ou movimentar a câmera, a inteligência artificial precisa prever como o cenário deve se transformar em resposta àquela ação. Os novos quadros gerados passam a fazer parte do contexto utilizado na próxima etapa da simulação. Dessa forma, o sistema opera em um ciclo contínuo no qual o usuário envia um comando, a IA interpreta a ação, o ambiente responde visualmente e o resultado passa a ser usado como ponto de partida para os próximos movimentos.
O modelo trabalha com oito comandos principais. As teclas W, A, S e D controlam a movimentação, enquanto I, J, K e L controlam a rotação da câmera ou do personagem. Esses comandos são sincronizados com os quadros do vídeo e inseridos diretamente na rede neural. Com isso, o modelo aprende que determinadas ações devem provocar mudanças específicas no ambiente virtual. Nas demonstrações, é possível caminhar por cenários abertos, explorar construções, controlar personagens, dirigir veículos, atravessar terrenos variados e reagir visualmente a obstáculos.
A experiência lembra um jogo eletrônico, mas existe uma diferença fundamental. Em um jogo tradicional, o mapa, os objetos, as animações, a iluminação e as regras de interação foram previamente criados e programados. No ABot-World-0, uma parte considerável do que aparece na tela é prevista e sintetizada pela inteligência artificial durante a própria execução. Em outras palavras, o ambiente não está sendo apenas exibido: ele está sendo continuamente imaginado pelo modelo.
Um mundo virtual executado em uma única GPU
Um dos aspectos mais impressionantes do ABot-World-0 é sua capacidade de funcionar em uma única NVIDIA GeForce RTX 5090, sem depender de um cluster composto por várias GPUs. O sistema consegue gerar vídeos com resolução de 1280 × 704 pixels, alcançando uma taxa de até aproximadamente 16 quadros por segundo. A latência entre o comando do usuário e a geração do primeiro quadro correspondente fica em torno de 1,2 segundo, enquanto o consumo máximo de memória gráfica permanece abaixo de aproximadamente 19,3 GiB de VRAM nas configurações otimizadas apresentadas pelos pesquisadores.
Esses números não significam que o projeto pode ser executado em qualquer computador doméstico. A RTX 5090 é uma placa de vídeo de alto desempenho e representa o segmento mais avançado das GPUs de consumo. Mesmo assim, executar uma simulação generativa desse nível em uma única placa instalada em um computador de mesa é muito diferente de depender de dezenas ou centenas de aceleradores operando em um data center.
O desempenho também varia conforme a precisão numérica utilizada durante a inferência. Na configuração FP8, que procura preservar maior qualidade visual, o sistema alcançou aproximadamente 12,4 FPS. Já na configuração MXFP4, mais comprimida e voltada para maior velocidade, o desempenho chegou a cerca de 15,8 FPS, valor divulgado de forma arredondada como até 16 FPS.
Ainda não estamos falando de uma experiência comparável aos 60, 120 ou 144 quadros por segundo encontrados em jogos modernos. A latência de 1,2 segundo também é perceptível e impede que o sistema seja considerado totalmente instantâneo. Entretanto, o resultado demonstra que a geração interativa de mundos virtuais começa a entrar em uma faixa de desempenho utilizável, especialmente para pesquisa, prototipagem, simulação e experiências visuais experimentais.
Como a inteligência artificial aprende a controlar um mundo
Para ensinar uma inteligência artificial a criar um ambiente interativo, não basta fornecer vídeos visualmente atraentes. O modelo precisa compreender qual ação provocou cada movimento mostrado na gravação. Ele precisa aprender, por exemplo, que pressionar uma tecla para a esquerda deve alterar a trajetória do personagem e modificar a perspectiva do cenário de maneira coerente.
Por isso, o treinamento do ABot-World-0 combina dados provenientes de jogos eletrônicos, ambientes simulados e vídeos reais encontrados na internet. Os jogos fornecem imagens detalhadas acompanhadas de comandos precisos. Nesse contexto, é possível registrar exatamente qual tecla foi pressionada, para onde o personagem se movimentou, como a câmera reagiu e quais mudanças ocorreram no ambiente.
Os simuladores oferecem ainda mais controle sobre elementos como posição da câmera, geometria, horário, clima, iluminação, trânsito, trajetória e movimentação de objetos. Já os vídeos reais da internet acrescentam diversidade de paisagens, condições de iluminação, perspectivas e situações encontradas no mundo físico. Como esses vídeos normalmente não possuem os comandos que deram origem ao movimento da câmera, o sistema precisa estimar o deslocamento e criar rótulos aproximados para as ações observadas.
O projeto também apresenta um agente autônomo chamado WorldExplorer, responsável por percorrer jogos e ambientes simulados automaticamente. Durante esse processo, ele coleta vídeos, posições de câmera, ações, trajetórias, estados do ambiente e outros metadados necessários para o treinamento. Quando os pesquisadores identificam que o modelo apresenta dificuldades em determinado cenário, movimento ou perspectiva, o sistema pode direcionar uma quantidade maior de coleta para aquela situação específica.
Isso cria um ciclo de melhoria contínua. O agente coleta os dados, o modelo é treinado, os erros são analisados e novas amostras são produzidas para corrigir as deficiências encontradas. Em vez de criar um conjunto de treinamento estático, os pesquisadores utilizam o próprio desempenho da inteligência artificial para orientar quais dados precisam ser coletados posteriormente.
Controle de qualidade e preservação dos personagens
Como dados ruins produzem modelos ruins, o material coletado passa por uma sequência de 14 verificações determinísticas, distribuídas em diferentes categorias de qualidade. O pipeline procura quadros ausentes, vídeos corrompidos, resoluções incorretas, falhas de sincronização, telas de carregamento, menus, elementos de interface, problemas de geometria, personagens atravessando objetos, comandos incompatíveis com o movimento, metadados incompletos e cenas visualmente inadequadas.
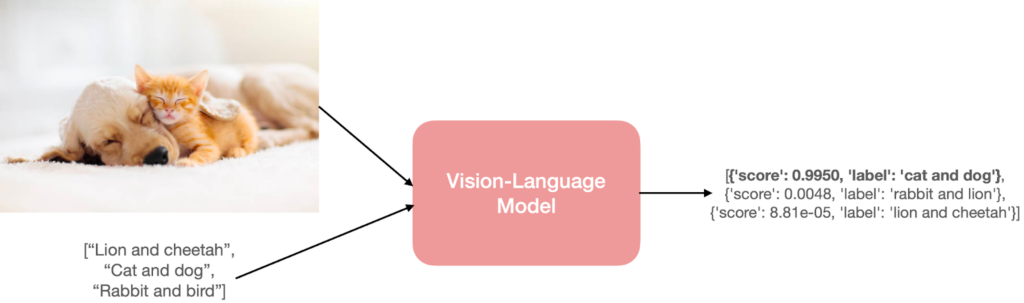
Além das verificações automáticas, um modelo de visão e linguagem analisa semanticamente os vídeos. Os trechos aprovados recebem informações sobre o tipo de cenário, clima, horário, veículo, perspectiva da câmera, personagem e ações executadas. Essa etapa torna os dados mais organizados e ajuda o modelo a compreender não apenas o movimento, mas também o contexto visual em que ele acontece.
Outro desafio importante é preservar a aparência dos personagens durante sequências prolongadas. Em vídeos longos gerados por inteligência artificial, um personagem pode mudar gradualmente de roupa, rosto, cabelo, proporção ou cor. Para reduzir esse problema, o pipeline extrai imagens de referência dos personagens em diferentes ângulos. Essas imagens ajudam o modelo a manter roupas, rosto, cores e identidade visual de maneira mais consistente, principalmente em cenas na terceira pessoa, nas quais o personagem permanece visível durante grande parte da experiência.
O modelo professor, o modelo aluno e o LongForcing
O treinamento utiliza uma estratégia semelhante à relação entre um professor e um aluno. Inicialmente, os pesquisadores treinam um modelo professor bidirecional, capaz de observar diferentes momentos de uma sequência completa. Como possui acesso a mais informações, esse modelo consegue aprender com maior qualidade a aparência das cenas, os movimentos, a dinâmica dos objetos e as consequências de cada ação.
Entretanto, o modelo professor não é adequado para uma aplicação em tempo real, pois depende de várias etapas de processamento e de uma visão mais ampla da sequência. Seu conhecimento é então transferido para um modelo aluno causal, que precisa trabalhar como o sistema funcionará durante o uso real: observando apenas o que já aconteceu e prevendo o próximo trecho do vídeo.
A transferência de conhecimento ocorre em três etapas. Na primeira, chamada Teacher Forcing, o aluno aprende a produzir os próximos quadros utilizando sequências corretas fornecidas durante o treinamento. Na segunda, conhecida como destilação ODE, o sistema reduz a quantidade de etapas necessárias para transformar o ruído inicial nos próximos quadros, acelerando significativamente a geração. Na terceira etapa entra o LongForcing, uma das principais contribuições apresentadas pelo projeto.
O LongForcing treina o modelo utilizando suas próprias gerações prolongadas. Em vez de trabalhar apenas com sequências perfeitas, o aluno precisa continuar produzindo novos quadros a partir das imagens que ele mesmo criou. O modelo professor analisa essas sequências e ajuda a corrigir os desvios que surgem ao longo do tempo. Essa técnica é essencial porque, em uma simulação contínua, qualquer pequeno erro pode ser reutilizado como contexto e acabar provocando falhas cada vez maiores.
O ABot-World-0 possui aproximadamente 5 bilhões de parâmetros, número relativamente compacto quando comparado a modelos com dezenas ou centenas de bilhões. Isso é particularmente relevante porque o sistema não trabalha apenas com texto. Ele precisa processar simultaneamente vídeo, movimento, ações, contexto temporal, aparência e dinâmica do ambiente. A pesquisa demonstra que modelos extremamente grandes nem sempre são indispensáveis quando a arquitetura, os dados, o treinamento e a inferência são cuidadosamente otimizados.
O desafio de gerar um mundo sem perder qualidade
Em um vídeo convencional de poucos segundos, pequenos erros podem passar despercebidos porque a sequência termina rapidamente. Em um mundo interativo, o problema é muito mais grave. Cada quadro criado pela inteligência artificial é utilizado como contexto para produzir os quadros seguintes. Um pequeno erro pode gerar outro erro maior, que passa a influenciar novas previsões e se acumula progressivamente.
Esse fenômeno é conhecido como drift, ou desvio acumulado. Com o passar do tempo, o personagem pode mudar de aparência, os objetos podem se deformar, os detalhes do cenário podem desaparecer e os movimentos podem se tornar repetitivos. Também podem surgir imagens borradas, cores excessivamente saturadas, texturas artificiais ou quadros praticamente congelados.
O LongForcing foi desenvolvido justamente para reduzir esse problema. Em vez de treinar o modelo apenas com trechos curtos e visualmente perfeitos, os pesquisadores também o expõem às previsões acumuladas que ele produz durante gerações prolongadas. O modelo professor observa essas sequências e ajuda o aluno a retornar para uma distribuição visual mais coerente.
Nos testes de 60 segundos, a técnica apresentou menos borrões, repetição de padrões, saturação excessiva e degradação visual do que outras configurações avaliadas. O artigo também apresenta exemplos retirados de gerações com duração de horas e testes realizados em escala de dias.
A expressão “geração infinita”, entretanto, precisa ser interpretada com cuidado. Ela não significa que o ambiente permanecerá perfeito para sempre nem que a inteligência artificial possuirá memória ilimitada sobre todos os lugares, objetos e acontecimentos. O termo indica que o sistema não possui uma duração fixa obrigatória, como ocorre com vídeos limitados a cinco ou dez segundos. Enquanto houver recursos computacionais e comandos do usuário, o modelo pode continuar produzindo novos quadros, embora inconsistências ainda possam surgir ao longo da experiência.
Otimização completa para caber em uma GPU
O desempenho alcançado pelo ABot-World-0 não depende apenas do modelo de inteligência artificial. Os pesquisadores precisaram otimizar toda a cadeia de execução, incluindo arquitetura, precisão numérica, memória, decodificação e kernels utilizados pela GPU.
Entre as principais tecnologias estão um decodificador de vídeo VAE mais leve, o processamento do Diffusion Transformer em baixa precisão, SageAttention2, uma implementação otimizada de RoPE, gerenciamento avançado de memória, cache KV com tamanho limitado, geração em blocos de quadros, FlashAttention, LightX2V e quantizações em FP8 e MXFP4.
A configuração original não cabia na memória da RTX 5090. O sistema tornou-se viável somente depois da combinação entre quantização, decodificador mais leve, kernels especializados e um gerenciamento mais eficiente da memória. Esse resultado traz uma lição importante para o desenvolvimento de soluções de IA: não basta possuir um bom modelo. Para transformar uma pesquisa em uma aplicação utilizável, é necessário otimizar conjuntamente software, arquitetura, memória e hardware.
Resultados apresentados no WorldRoamBench
O ABot-World-0 foi avaliado no WorldRoamBench, benchmark voltado para modelos de mundos interativos. A avaliação considera a capacidade de responder aos comandos, acompanhar trajetórias, preservar a qualidade visual, reproduzir comportamentos físicos e manter informações ao longo do tempo.
O modelo alcançou 0,5266 de precisão estrita no controle das ações, ficando muito próximo da melhor pontuação apresentada na comparação, que foi de 0,5317. Também obteve 0,7290 em precisão parcial, 0,6752 no acompanhamento de trajetória, 0,5039 em estética, 0,4651 em qualidade de imagem, 0,5223 em mecânica e 0,5041 em memória.
| Métrica | Resultado |
|---|---|
| Precisão estrita das ações | 0,5266 |
| Precisão parcial | 0,7290 |
| Acompanhamento de trajetória | 0,6752 |
| Estética | 0,5039 |
| Qualidade da imagem | 0,4651 |
| Mecânica | 0,5223 |
| Memória | 0,5041 |
Os resultados demonstram um desempenho competitivo, mas não uma vitória em todas as categorias. Outros modelos apresentaram pontuações superiores em determinados critérios, principalmente na retenção de memória. Ainda assim, o ABot-World-0 consegue oferecer resultados relevantes utilizando um modelo relativamente compacto e uma única GPU de desktop.
Os exemplos divulgados pelos pesquisadores incluem veículos colidindo com objetos, personagens deixando marcas na neve, movimentos criando rastros na água e obstáculos impedindo a passagem. Isso não significa, entretanto, que o modelo possua um mecanismo tradicional de física.
O ABot-World-0 não foi programado com regras matemáticas explícitas de colisão, gravidade ou dinâmica. Ele aprendeu esses comportamentos observando grandes quantidades de vídeos e ambientes interativos. As respostas físicas podem parecer plausíveis, mas não devem ser tratadas como uma simulação científica exata. O modelo apenas prevê visualmente o que provavelmente deveria acontecer com base nos exemplos vistos durante o treinamento.
Código aberto e possíveis aplicações
O código de inferência, a demonstração local com Gradio e o modelo causal ABot-World-0-5B-LF foram disponibilizados publicamente. O projeto utiliza a licença Apache 2.0, e os pesos podem ser encontrados em plataformas como Hugging Face e ModelScope.
O ambiente oficialmente testado utiliza Ubuntu 22.04, Python 3.12, CUDA 12.8, PyTorch 2.8, NVIDIA RTX 5090, FlashAttention, SageAttention e LightX2V. A instalação ainda exige a compilação de componentes especializados e não é tão simples quanto instalar um programa convencional. O modelo professor bidirecional e o conjunto completo de aproximadamente 500 horas de vídeos acompanhados de ações anotadas aparecem no planejamento do projeto, mas ainda não estavam totalmente disponibilizados na publicação inicial.
Tecnologias como o ABot-World-0 podem transformar diferentes setores. Na indústria de jogos, desenvolvedores poderão criar protótipos de ambientes que se expandem durante a exploração, reduzindo o tempo necessário para testar conceitos visuais, cenários e mecânicas. Na robótica, agentes autônomos poderão ser treinados em ambientes virtuais antes de serem testados no mundo real. Na realidade virtual, cada usuário poderá explorar espaços personalizados e potencialmente diferentes a cada sessão.
Na educação, estudantes poderão visitar reconstruções interativas de cidades antigas, ecossistemas, laboratórios e acontecimentos históricos. Na produção audiovisual, diretores e artistas poderão navegar por conceitos visuais antes de transformar uma ideia em uma cena tradicional. Também existem possíveis aplicações em direção autônoma, treinamento industrial, planejamento urbano e criação de grandes volumes de dados sintéticos para o treinamento de outros sistemas de inteligência artificial.
Ainda é uma tecnologia experimental
Apesar dos resultados impressionantes, o ABot-World-0 ainda deve ser entendido como um projeto de pesquisa. A experiência depende de uma RTX 5090, apresenta uma latência perceptível e não alcança a taxa de quadros típica dos jogos modernos. O sistema também pode produzir inconsistências, esquecer detalhes antigos, interpretar ações incorretamente, deformar objetos, alterar a aparência dos personagens ou gerar comportamentos fisicamente impossíveis.
O documento publicado no arXiv é um preprint, ou seja, um artigo disponibilizado antes de uma revisão científica mais ampla. Os resultados foram apresentados pelos próprios pesquisadores e ainda precisam ser reproduzidos de maneira independente pela comunidade.
O projeto demonstra uma direção tecnológica promissora, mas ainda não elimina a necessidade de motores gráficos, geometria 3D, física programada, lógica criada por desenvolvedores e validação humana. No futuro, é provável que modelos generativos sejam combinados com essas tecnologias tradicionais, e não simplesmente utilizados para substituí-las.
O futuro dos mundos gerados por inteligência artificial
O ABot-World-0 mostra que a geração de vídeo está deixando de ser apenas uma ferramenta para produzir pequenos clipes. A próxima etapa pode ser a criação de ambientes que respondem, mudam e continuam existindo enquanto são explorados.
Seu principal avanço não está apenas na qualidade visual, mas na combinação entre controle por ações, geração prolongada, preservação de personagens, redução do desvio acumulado, otimização de memória e execução em uma única GPU.
Ainda estamos longe de substituir completamente os motores gráficos convencionais. Porém, o projeto oferece uma demonstração concreta de como poderão funcionar os jogos, simuladores e ambientes virtuais do futuro. Em vez de mundos totalmente armazenados em arquivos e previamente construídos, poderemos explorar ambientes que são imaginados e renderizados pela inteligência artificial em tempo real.
Vídeo e links do projeto
Abaixo um vídeos demonstrativo e links com fontes, paper e informatização técnicas.
Código-fonte no GitHub:
https://github.com/amap-cvlab/ABot-World
Página oficial do projeto:
https://amap-cvlab.github.io/ABot-World/
Artigo científico no arXiv:
https://arxiv.org/abs/2607.19191