
Quero começar este post, mencionando que não usei o Chat-GPT e sim minha esposa Gisele que corrige 90% dos meus textos. Logo os 10% publicados na internet com erros, foram os que ela não corrigiu! Mas voltando ao ponto focal, eu acreditava que a Visão Neuromórfica seria o futuro da Visão Computacional. E aparentemente eu estava enganado, pois a arquitetura Transformers está derivando em tecnologia que será capaz de ler nossos lábios durante conversar nas ruas das imagens em câmeras públicas de monitoramento.
Esta minha afirmação, deve-se que em 2017, foi publicado um paper chamado “Attention Is All You Need” [1], que apresentava um novo modelo de rede neural focado no processamento de Linguagem Natural. Hoje conhecido como Transformers que deu origem ao ChatGPT da openAI(seq2seq).

Hoje estamos com uma avalanche informacional no setor de redes neurais. O assunto da moda chamada Transformers é a primeira revolução de mais dois assuntos que merecem atenção e ficarão para os próximos posts. Este novo modelo foi focado em NLP (Processamento de Linguagem Natural). Em 2020 terminei os testes com o GPT-3 e postei aqui no assunto nerd.O que mais chamou a minha atenção nesta tecnologia foi o Mecanismo de Atenção. Esta técnica mudou tudo, até minha maneira de ver os meus trabalhos técnicos. O conceito foca na informação de dados ruidosos, assim resolvendo o gargalo representativo baseado no score de atenção.
Não vou perder tempo com o Chat GPT, pois a mídia já fez isto muito bem. Então, podemos dizer que o esforço cognitivo do GPT-3 ou 4 é a maneira diferenciada de processar / interpretar o contexto.
Em 2021 outro paper [2] surgiu com uma nova proposta de rede neural. Focada em melhorar como as máquinas enxergam. A Vision Transformer ou ViT, é uma arquitetura muito semelhante ao modelo Transformers proposto em 2017. Com pequenas alterações para processar imagens em vez de textos.
Até aqui, as redes neurais convolucionais foi o estado da arte em visão computacional. O seu processamento é baseado nos kernels convolucionais para reconhecer as características dos objetos. É uma saga treinar um CNN. O ViT tem a proposta de não imitar o conceito do Transformes, pois o conceito de Mecanismo de Atenção para cada pixel seria inviável em termos de custo computacional. Ai veio a genialidade do paper, o modelo divide a imagem em unidades quadradas (denominada tokens). O padrão é 16×16. Assim aplicando o Self-Attention em cada parte da imagem. Com isto a velocidade é impressionante, pois o ViT varre a imagem com 90% de precisão.
Nos testes de processamento de imagem em 14/03, uma versão do ViT assumiu o primeiro lugar, o segundo lugar foi para um modelo que combinou CNN com Transformers. Para entenderem o contexto, as melhores CNNs de longa data, não chegaram perto desta nova abordagem. Agora em 16/04/2023 modelos Transformes+CNN atingiram o primeiro lugar.
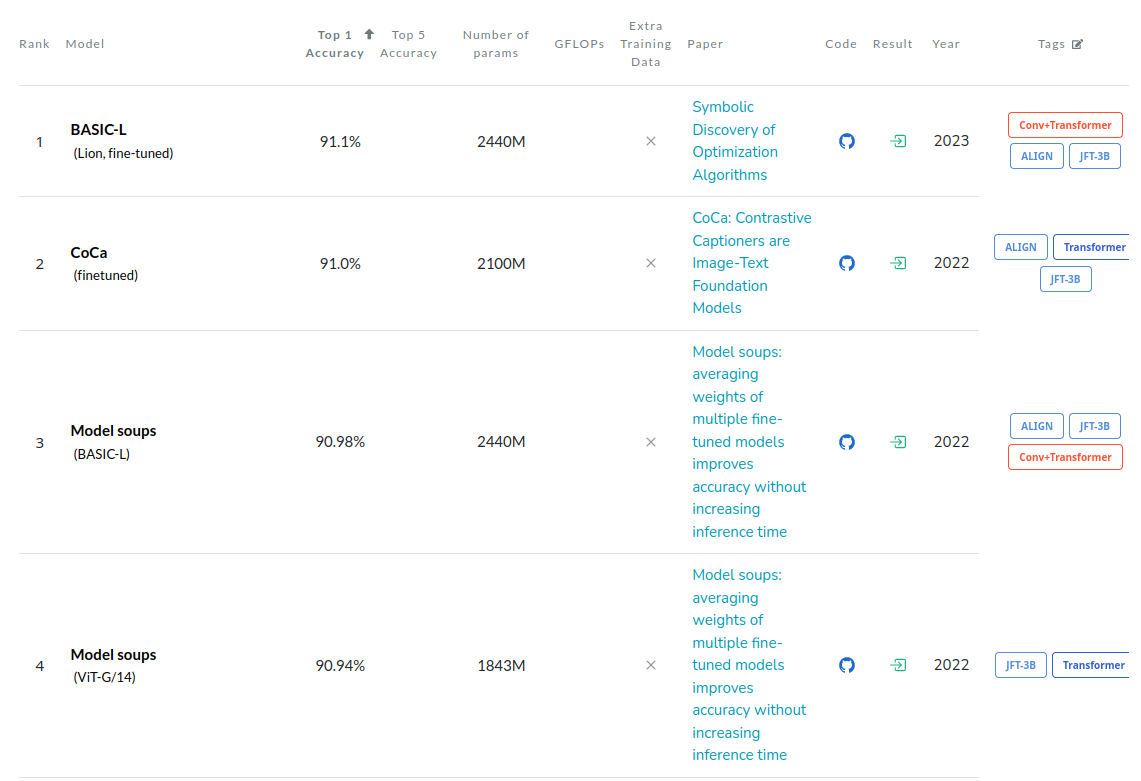
Estou empolgado, pois aplicar o mecanismo de atenção na entrada (encoders) pode ser um grande passo na arquitetura de redes neurais, assim resultando uma nova abordagem no setor de visão computacional.
Os Transformers estão sendo explorados em arquiteturas de aprendizado de máquina multimodais, que são habilitadas para processar diversos tipos de dados, como áudio, vídeo e imagens. Um paper [3] faz uma abordagem onde redes multimodais podem ser usadas para criar sistemas que compreendem a fala e leem os lábios de uma pessoa simultaneamente.
Problema: “não tem almoço grátis”, a arquitetura Transformers tem um alto custo de processamento na fase de pré-treinamento para superar a precisão dos modelos concorrentes. Treinar imagem é uma saga enorme. Mas para terminar, existem estudos sobre diminuir este custo computacional, como Transformes com filtro que podem ser implementados em CNNs. Então teremos muitas novidades disruptivas no setor de IA.
Referencias científicas:
[1] Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N; Kaiser, Lukasz; Polosukhin, Illia. (2017). “Attention Is All You Need”. arXiv:1706.03762 [cs]. arXiv.org, http://arxiv.org/abs/1706.03762.
[2] Dosovitskiy, Alexey, et al. (2021). “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”. arXiv:2010.11929 [cs]. arXiv.org, http://arxiv.org/abs/2010.11929.
[3] Akbari, Hassan; Yuan, Liangzhe; Qian, Rui; Chuang, Wei-Hong; Chang, Shih-Fu; Cui, Yin; Gong, Boqing. (2021). “VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text”. arXiv:2104.11178 [cs, eess]. arXiv.org, http://arxiv.org/abs/2104.11178.
