Fui surpreendido pelo desempenho de uma inteligência artificial de um projeto chinês. Ao enviar uma foto minha com minha mãe, uma cena de filme e outra foto minha na praia, os resultados foram impressionantes. Confira as respostas obtidas ao questionar sobre o aspecto emocionante da imagem, o objeto que eu segurava e a cor da minha camisa:

“A parte mais emocionante desta foto é o abraço amoroso entre você e sua mãe. Vocês dois estão se abraçando com força, mostrando a forte conexão e vínculo que compartilham. Além disso, o fato de você estar segurando um copo plástico com cerveja na mão torna esse momento mais pessoal, pois mostra que vocês estão desfrutando de uma atividade compartilhada ou de um momento de descontração juntos. Esta foto captura um momento caloroso e terno entre você e sua mãe, e provavelmente é uma lembrança que você aprecia.”
projeto: mPLUG-Owl
O paper “mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality” [1] disponibilizado dia 27 de Abril de 2023 às 13:27:01 UTC menciona que Large languade models (LLMs) demonstraram habilidades impressionantes em uma variedade de tarefas, enquanto pesquisas recentes também exploraram o uso de LLMs para geração multimodal.
Neste estudo é apresentado o mPLUG-Owl, um novo paradigma de treinamento que insere aos LLMs habilidades multimodais com aprendizagem modularizada do LLM base, um módulo de conhecimento visual e um módulo abstrator visual. O paradigma de treinamento do mPLUG-Owl envolve um método de duas etapas para alinhar imagem e texto, aprendendo os dados visuais com a assistência do LLM enquanto mantém e até melhora as habilidades de geração do LLM.
Na primeira fase, o módulo de conhecimento visual e o módulo abstrator são treinados com um módulo LLM para alinhar a imagem e o texto. Já na segunda etapa, conjuntos de dados supervisionados apenas de linguagem e multimodais são usados para ajustar conjuntamente um módulo de low-rank adaption (LoRA) no LLM e no módulo abstrator, congelando o módulo de conhecimento visual.
Os resultados experimentais mostram que o modelo supera os modelos multimodais existentes, demonstrando a impressionante habilidade de instrução e compreensão visual do mPLUG-Owl, habilidade de conversação em várias etapas e habilidade de raciocínio de conhecimento.
Mas o que mais me surpreendeu foi algumas habilidades inesperadas e interessantes, como correlação entre várias imagens e compreensão de texto em cena, o que torna possível aproveitá-lo para cenários reais mais difíceis, como compreensão de documentos apenas com visão. Nosso código, modelo pré-treinado, modelos ajustados por instrução e conjunto de avaliação estão disponíveis neste URL https://github.com/X-PLUG/mPLUG-Owl
Abaixo, mais alguns testes:
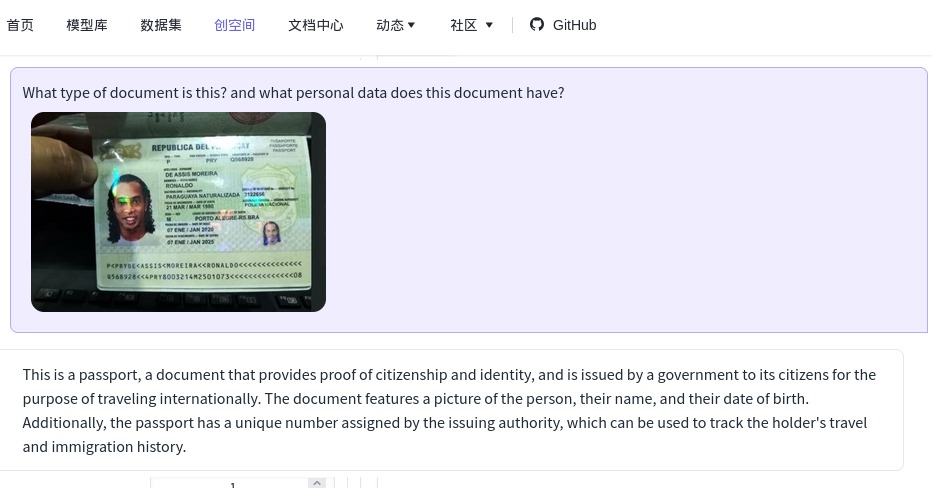
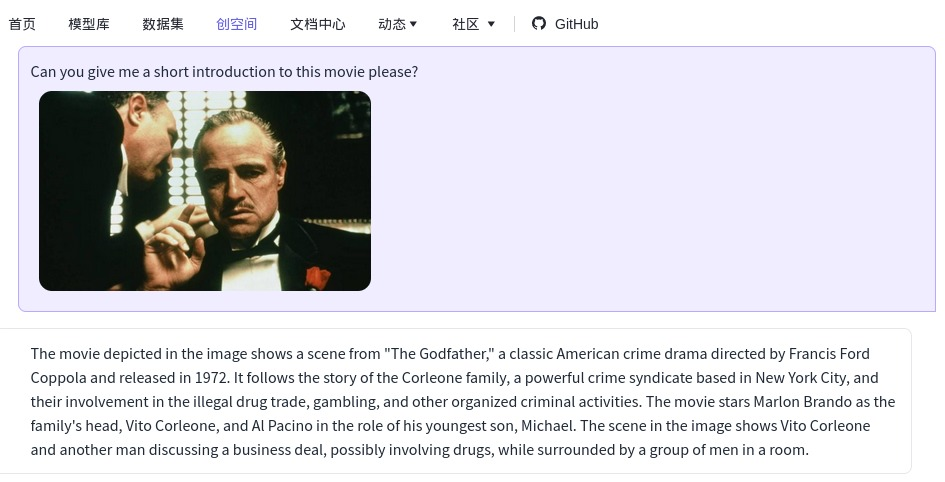

https://arxiv.org/pdf/2304.14178.pdf
Referencias científicas:
[1] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qian Qi, Ji Zhang, Fei Huang (2023). “mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality”. arXiv:2304.14178 [cs]. arXiv.org, https://arxiv.org/abs/2304.14178
