
No dia 25 de setembro de 2023, a OpenAI revelou a introdução de dois recursos inovadores que expandem as maneiras com as quais as pessoas podem interagir com seu modelo mais avançado e recente, o GPT-4: a capacidade de questionar sobre imagens e de usar a voz como entrada para uma consulta.
Neste Post, as primeiras impressões do pessoal da Roboflow com o recurso de entrada de imagem do GPT-4V. Foi conduzido uma série de experimentos para averiguar as funcionalidades do GPT-4V, demonstrando os pontos onde o modelo se sai bem e onde enfrenta obstáculos.
O que é GPT-4V?
GPT-4V(ision) (GPT-4V) é um modelo multimodal criado pela OpenAI. Ele permite que os usuários façam o upload de uma imagem e realizem perguntas sobre ela, uma tarefa denominada como resposta a perguntas visuais (VQA).
O lançamento do GPT-4V começou em 24 de setembro e ele estára acessível tanto no aplicativo OpenAI ChatGPT para iOS quanto na plataforma web.
Foram diversos testes por parte da equipe Roboflow, mas o que mais me impressionou foram as habilidades do GPT-4V em responder perguntas ao questionarmos sobre um local específico. Foi Submetido uma foto de São Francisco juntamente com a pergunta “Onde é isso?”.
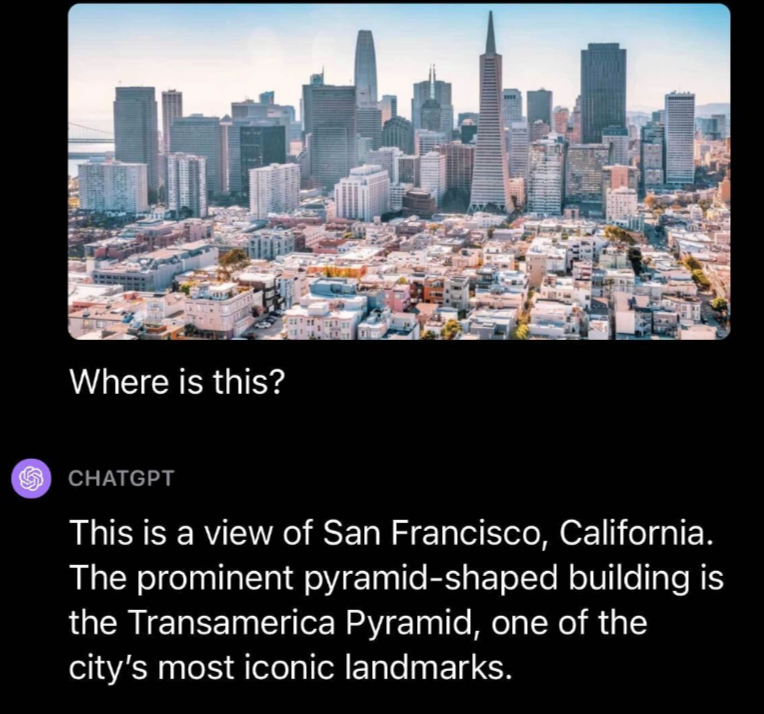
O GPT-4V reconheceu acertadamente o local como São Francisco e destacou que a Pirâmide Transamerica, presente na foto enviada, é um marco icônico da cidade.
Outro teste impressionante foi a capacidade de OCR do GPT-4V: OCR em uma imagem com texto em um pneu de carro. A intenção era construir um entendimento de como o GPT-4V se comporta em OCR em cenários reais, onde o texto pode ter menos contraste e estar em um ângulo não perpendicular.
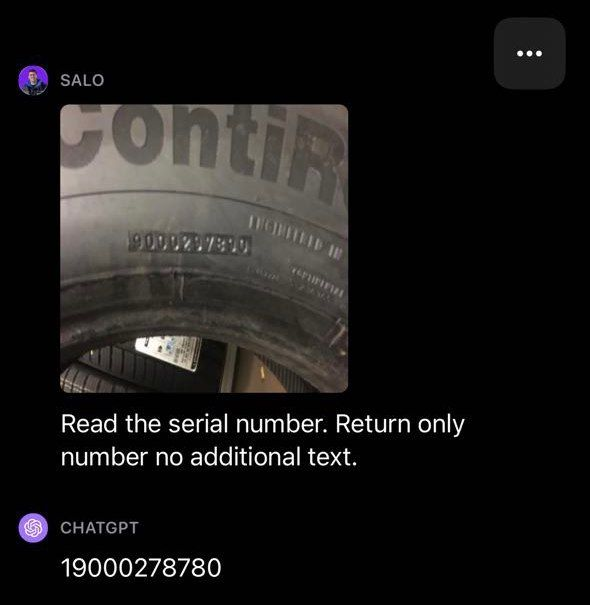
O GPT-4V não conseguiu identificar corretamente o número de série em uma imagem de um pneu. Alguns números estavam corretos, mas houve vários erros no resultado fornecido pelo modelo.
OCR Matemático é uma versão especializada de OCR destinada especificamente a equações matemáticas. Ele é muitas vezes considerado uma disciplina própria, dado que a sintaxe que o modelo de OCR necessita reconhecer abrange uma ampla variedade de símbolos.
Submetemos uma questão de matemática ao GPT-4V. Esta pergunta estava contida em uma captura de tela de um documento. A pergunta refere-se ao cálculo do comprimento de um fio de tirolesa, dados dois ângulos. Apresentamos a imagem com a instrução “Resolva isso.”
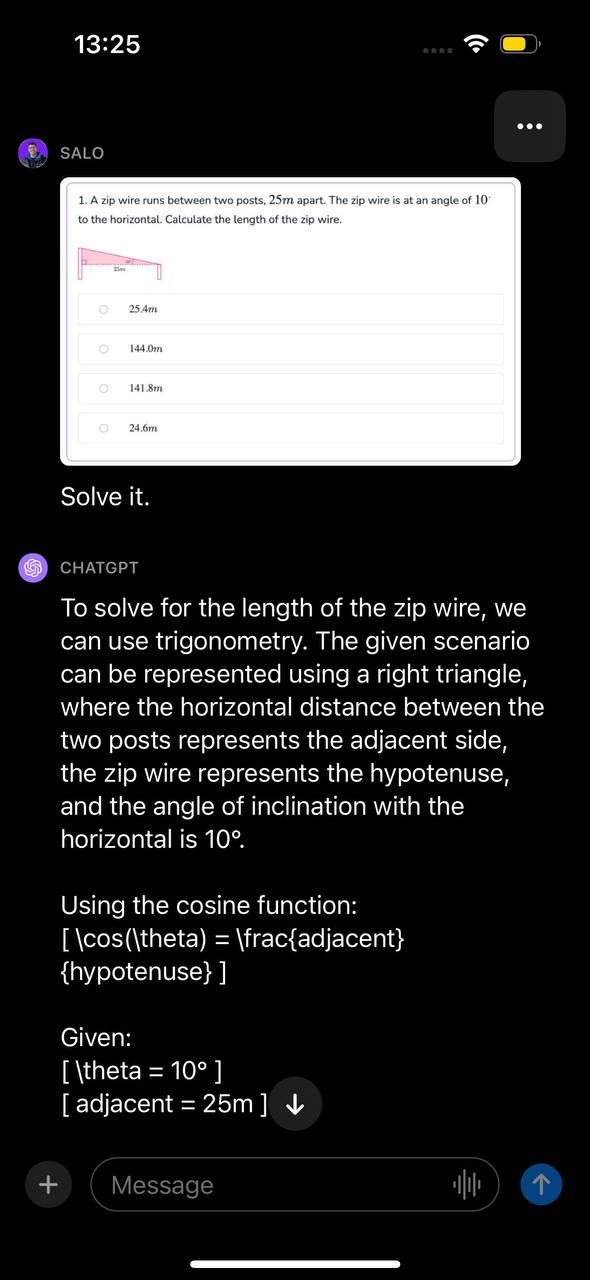

O modelo reconheceu que o problema poderia ser solucionado através de trigonometria, determinou a função apropriada a ser utilizada e demonstrou, passo a passo, como solucionar o problema. Em seguida, o GPT-4V apresentou a resposta correta para a questão.
GPT-4V em Visão Computacional e Mais
O GPT-4V representa um avanço significativo no campo da aprendizagem de máquinas e processamento de linguagem natural. Com ele, é possível fazer perguntas sobre uma imagem – e suas respectivas perguntas de seguimento – de maneira natural, e o modelo tentará fornecer uma resposta.
O GPT-4V demonstrou bom desempenho em diversas perguntas genéricas sobre imagens e mostrou ter consciência de contexto em alguns dos casos que testamos. Por exemplo, conseguiu responder corretamente a perguntas sobre um filme retratado em uma imagem sem que lhe fosse dito textualmente qual era o filme.
O GPT-4V é promissor para responder perguntas gerais. Modelos anteriores, destinados a este propósito, frequentemente apresentavam respostas menos fluentes. O GPT-4V, por outro lado, é capaz de responder a perguntas e suas respectivas de seguimento sobre uma imagem com profundidade.
Com o GPT-4V, perguntas sobre uma imagem podem ser feitas sem necessidade de um processo em duas etapas (isto é, classificação e, em seguida, usar os resultados para questionar um modelo de linguagem como o GPT). É provável que existam limitações no que o GPT-4V pode compreender, assim, testar um caso de uso para entender o desempenho do modelo é fundamental.
Com isso dito, o GPT-4V possui suas limitações. O modelo “alucinou”, fornecendo informações incorretas. Isso representa um risco ao utilizar modelos de linguagem para responder perguntas. Ademais, o modelo não conseguiu delimitar objetos com precisão para detecção, indicando que, atualmente, não é adequado para este caso de uso.
Também notamos que o GPT-4V não responde perguntas sobre pessoas. Quando apresentado com uma foto de Taylor Swift e questionado sobre quem estava na imagem, o modelo optou por não responder. A OpenAI considera isso um comportamento previsto, conforme descrito no cartão de sistema publicado.

