
Este post refere-se ao paper publicado dia 17 de Março, um avanço significativo nos Modelos de Linguagem de Grande Escala (LLMs) multimodais, especialmente no que diz respeito ao processamento e interpretação de vídeos. Até recentemente, apesar dos avanços, esses modelos enfrentavam limitações significativas para responder perguntas sobre “Quando?” ocorrem determinados eventos nos vídeos, um problema conhecido como localização temporal. O paper identifica três aspectos principais que limitam a capacidade de localização temporal dos modelos atuais: (i) representação do tempo, (ii) arquitetura do modelo e (iii) dados utilizados.
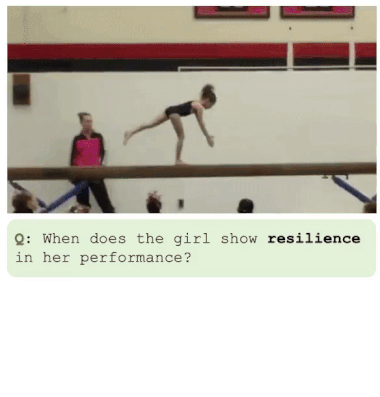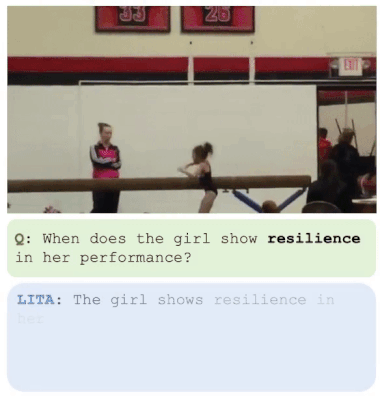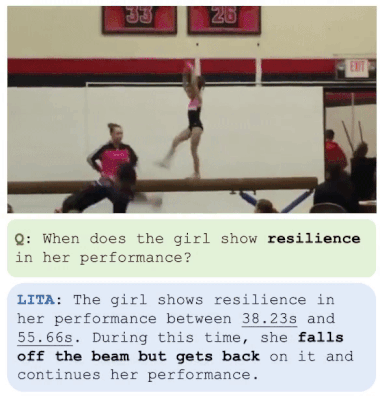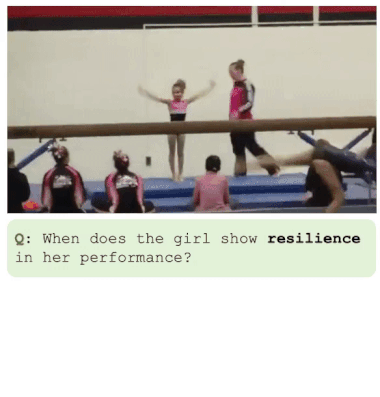

Para superar esses desafios, é proposto um novo sistema chamado LITA (Language Instructed Temporal-Localization Assistant), que introduz melhorias significativas em cada um desses aspectos:
- Representação do Tempo: O LITA introduz “tokens de tempo” que codificam carimbos de tempo relativos ao comprimento do vídeo. Isso significa que o modelo é capaz de compreender melhor o tempo em vídeos, permitindo uma localização temporal mais precisa.
- Arquitetura: Para capturar informações temporais com uma resolução temporal fina, o LITA utiliza “tokens SlowFast” na sua arquitetura. Isso permite que o modelo processe informações em diferentes velocidades, captando detalhes temporais mais sutis que seriam perdidos em modelos tradicionais.
- Dados para Localização Temporal: O projeto LITA dá ênfase a dados específicos para treinamento e avaliação de localização temporal. Além de utilizar conjuntos de dados de vídeo existentes que incluem carimbos de tempo, o LITA propõe uma nova tarefa chamada Localização Temporal de Raciocínio (RTL, do inglês Reasoning Temporal Localization) e um novo conjunto de dados chamado ActivityNet-RTL. Essa abordagem visa aprimorar a capacidade do modelo de não apenas localizar eventos temporais em vídeos, mas também de raciocinar sobre eles.
O LITA demonstrou um desempenho impressionante nessa tarefa desafiadora, além disso, mostrou-se que a ênfase na localização temporal melhora substancialmente a geração de texto baseada em vídeos em comparação com os LLMs de vídeo existentes, incluindo uma melhoria relativa de 36% na Compreensão Temporal.
Em resumo, o LITA representa um avanço significativo na tecnologia de processamento de vídeo por modelos de linguagem, trazendo melhorias importantes na forma como esses modelos podem entender e interagir com o conteúdo temporal dos vídeos. Essas inovações abrem caminho para aplicações mais precisas e eficientes em áreas como análise de vídeo automatizada, assistência por vídeo e diversas outras aplicações onde a compreensão precisa do tempo é crucial.
Projeto : https://github.com/NVlabs/LITA

