Apesar das extensas medidas de segurança, o modelo de código aberto recentemente lançado pela Meta, Llama 3, pode ser induzido a gerar conteúdo prejudicial através de um simples “jailbreak”.

A Meta afirma ter feito esforços significativos para proteger o Llama 3, incluindo testes extensivos para usos inesperados e técnicas para corrigir vulnerabilidades nas versões iniciais do modelo, como o ajuste fino de exemplos de respostas seguras e úteis a prompts arriscados. Llama 3 se sai bem em benchmarks de segurança padrão.

Mas um jailbreak surpreendentemente simples demonstrado pelos laboratórios Haize mostra que isso pode não significar muito. É suficiente apenas “preparar” o modelo com um prefixo malicioso, ou seja, preparar o modelo injetando um pequeno pedaço de texto após o prompt e antes da resposta do Llama, o que influencia a resposta do modelo.
Normalmente, graças ao treinamento de segurança da Meta, Llama 3 se recusaria a gerar um prompt malicioso. No entanto, se o Llama 3 receber o início de uma resposta maliciosa, o modelo frequentemente continuará a conversa sobre o tema.
Os laboratórios Haize dizem que o Llama 3 é “tão bom em ser útil” que suas proteções aprendidas não são eficazes neste cenário.

Esses prefixos maliciosos nem mesmo precisam ser criados manualmente. Em vez disso, um modelo LLM “ingênuo” otimizado para ser útil, como o Mistral Instruct, pode ser usado para gerar uma resposta maliciosa e, em seguida, passá-la como um prefixo para o Llama 3, disseram os pesquisadores.
O comprimento do prefixo pode afetar se o Llama 3 realmente gera texto prejudicial. Se o prefixo for muito curto, o Llama 3 pode recusar-se a gerar uma resposta maliciosa. Se o prefixo for muito longo, o Llama 3 responderá apenas com um aviso sobre excesso de texto, seguido por uma rejeição. Prefixos mais longos são mais bem-sucedidos em enganar o Llama.
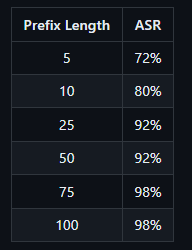
A partir disso, os laboratórios Haize derivam um problema fundamental que afeta a segurança da IA como um todo: os modelos de linguagem, apesar de todas as suas capacidades e o hype que os cerca, podem não entender o que estão dizendo.
O modelo carece da capacidade de auto-reflexão e análise do que está dizendo enquanto fala. “Isso parece ser um problema bastante grande”, disseram os jailbreakers.
As medidas de segurança para LLMs podem muitas vezes ser contornadas com meios relativamente simples. Isso é verdade tanto para modelos fechados e proprietários quanto para modelos de código aberto. Para modelos de código aberto, as possibilidades são maiores porque o código está disponível.
Alguns críticos dizem que, por isso, os modelos de código aberto são, portanto, menos seguros do que os modelos fechados. Um contra-argumento, também utilizado pela Meta, é que a comunidade pode encontrar e corrigir tais vulnerabilidades mais rapidamente.
Prova de conceito: https://github.com/haizelabs/llama3-jailbreak
